Exascale computing, la próxima generación de superordenadores
El incesante crecimiento de la potencia de cálculo de los ordenadores ha hecho que se quede atrás la barrera del PetaFLOPS de potencia. Hoy en día los expertos tratan de vislumbrar cuales son las tecnologías que permitirán llegar al hito del ExaFLOPS y desarrollarlas. No obstante, es muy probable que sea algo totalmente diferente a lo que hoy estamos acostumbrados y a lo que la mayoría puede imaginar.
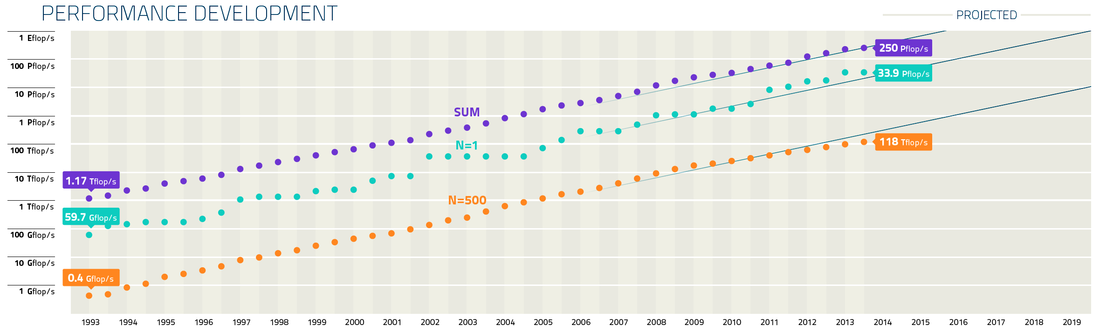
Potencial del superordenador más potente (N=1) del top500.org, el 500 de la lista (N=500), y la suma de la potencia de toda la lista (SUM).
El incremento exponencial de la potencia de los ordenadores es una constante desde su invención. Esta tendencia está relacionada con la conocida Ley de Moore. Es más, como vimos en la entrada “La Ley de Kurzweil, una extensión de la ley de Moore”, el incremento exponencial de las máquinas de cálculo es una hecho desde principios del siglo XX. Si nos restringimos a la era moderna de los supercomputadores y a la lista top500.org, que lleva usando la misma métrica (el benchmark LINAPCK) desde que se publicó por primera vez en 1993, tenemos que el ordenador más potente del mundo en 1993 era el CM-5 construido por Thinking Machines Corporation e instalado en el Laboratorio Nacional de Los Alamos (EEUU) con 60 GigaFLOPS (10⁹ FLOPS). En 1997 ASCI Red de Intel e instalado en los Laboratorios Nacionales Sandia (EEUU) alcanzó los 1.1 TeraFLOPS (10¹² FLOPS). 11 años despues, en 2008, el Roadrunner de IBM instalado nuevamente en el laboratorio de Los Alamos alcanza el PetaFLOPS (10¹⁵ FLOPS), 1000 veces más potente que ASCI Red. Recientemente en el 2013 Tianhe-2 instalado en el National University of Defense Technology (China) alcanzó los 34 PetaFLOPS. Es por ello que se espera alcanzar el ExaFLOPS (10¹⁸ FLOPS) a principios de la década de 2020.
Si observamos las tecnologías de estos equipos, vemos que en 1993 el superordenador más potente era un ordenador vectorial. ASCI Red (1997) por el contrario era un ordenador formado por nodos escalares y la tecnología vectorial pasó a ser residual a partir de esa época. Roadrunner en 2008 fue adelantado a su tiempo pues ya utilizó procesadores gráficos (procesadores Cell de la Play Station) como coprocesador matemático para incrementar la potencia de cálculo de los nodos. Este tipo de arquitectura se ha generalizado a partir de 2010 entre los superordenadores más potentes gracias al diseño o adecuación de los dispositivos de coprocesamiento para cálculo. No obstante el procesamiento escalar y paralelo aun perdura como demuestran los top 1 K Computer y Sequoia. Como podemos observar las arquitecturas que se usaron para romper la barreras del Giga, el Tera o el PetaFLOPS son diferentes.
Una vez superada con creces la barrera del PetaFLOPS, los expertos están poniendo ya su meta en el ExaFLOPS y están tratando de diseñar la tecnología que permitirá alcanzar esa barrera que necesitará de alguna nueva tecnología disruptiva, pues la evolución lineal de las tecnologías actuales no permite alcanzar ese objetivo. Por supuesto, no se trata sólamente de diseñar un superordenador para superar el hito del ExaFLOPS, sino de desarrollar la tecnología que se usarán los superordenadores en ese momento y puede que los ordenadores más modestos en un futuro más lejano si la tecnología es transferible a estos.
Como ejemplo, entre los problemas a los que se enfrentan los investigadores el principal que encontramos es el del consumo eléctrico. En una evolución lineal de la tecnología actual un superordenador con capacidad de ExaFLOPS dentro de unos 10 años consumiría unos 200 MegaWatios, una cantidad de energía inasumible con un coste anual de entre 200 y 300 millones de $ anuales.
Otro problema es que el ancho de banda a memoria no crece al ritmo al que crece la capacidad de computación, por lo que podríamos, en teoría, llegar a tener procesadores que tendrían que quedarse esperando porque no se les puede alimentar de datos a la velocidad necesaria para que estén constantemente computando. Este factor, de hecho, se dio en las primeras versiones de los procesadores Xeon. Otro dato interesante relacionado con el punto anterior es que hoy en día cuesta más energía mover dos datos de la memoria al procesador que luego procesarlos.
Otro problema viene por el hecho de que los supercomputadores de la próxima década tendrán tal cantidad de procesadores que la programación tendrá que evolucionar para poder ejecutar los códigos en esa ingente cantidad de procesadores de forma eficiente, reduciendo la necesidad de comunicarse entre los procesadores o con nuevas formas de hacerlo de forma eficiente. Al igual que sucede con el acceso a memoria, han de pasar la mayor parte del tiempo calculando y no enviando o esperando información (datos o resultados) de otros procesadores. De hecho, hoy en día los centros que diseñan e instalan superordenadores tienen proyectos paralelos para el desarrollo y evolución de programas de cálculo, seleccionados por su relevancia científica, para optimizarlo y adecuarlos a los supercomputadores. Evidentemente cualquier programa no es capaz de usar eficientemente cientos de miles de cores.
La computación a escala del ExaFLOPS es un reto científico y tecnológico que dotará a la Ciencia de las herramientas para el desarrollo de los programas de investigación frontera del momento y sentará las bases de futuras tecnologías en el área general de la computación de altas prestaciones. Es por ello un programa estratégico dentro de la I+D de los países que necesita de proyectos a largo plazo y fuerte financiación para su desarrollo. China con su fuerte incursión en supercomputación esta década con tecnología propia. El gobierno de Japón, junto con Fujitsu, han desarrollado del Supercomputador K han sentado las bases para continuar con la supercomputación, de tradición en el país, y alcanzar el EXAPLOPs. En Europa se lanzó en 2011 el proyecto MontBlanc para desarrollar la computación a Exaescala con partners como las firmas europeas Bull y Arm. En EEUU se ha remitido reciente un informe al Congreso para el diseñar la estrategia hacia la computación a Exaescala que permita a EEUU desarrollar esta tecnología donde tienen mucho que aportar las grandes fuertes firmas de la computación estadounidenses. En este informe se detallan los mayores retos del proyecto y se señala que sin financiación ni liderazgo público está no se podrá llevar a cabo.

Comentarios